안녕하세요?
지난 주말에 친구의 부탁으로 정부기관 사이트(gosi.kr)를 파싱해서 텔레그램 봇으로 새글알림을 하는 코드를 짜봤습니다.
텔레그램 봇과 관련해서는 매우 허접하지만 이미 작년에도 제가 스포어에 글을 올렸기 때문에
원래 작성한 코드를 조금 변형해서 PC통신이나 텍스트 기반 브라우저처럼 열람하고 싶은 게시글 번호를 입력하면
해당 게시글의 내용을 출력해주는 것으로 수정했습니다.
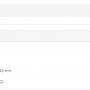
해당 웹페이지는 정부기관의 공고와 관련된 것으로서
저작권법 등 관련법률에 저촉되지 않는다고 생각되어서 코드를 올립니다.
소스는 파이썬 3.7에서 작성되었으며
다른 스포어 회원님들께서 기본적으로 알고계실 수준의 아주 기초적인 BeautifulSoup과 정규식을 사용했습니다.
작성하고보니 파이썬이 추구하는 아름답고 간결한 코딩과는 굉장히 거리가 멀지만
(아스날의 아름다운 축구를 보다가 이란의 침대축구를 보는 것처럼 가슴이 답답해지는군요 -_-;;;)
일단 2018년 9월 현재 기준으로 오류 없이 돌아가는 데에 의의를 두겠습니다 ㅠㅠ
1~10까지 게시글 번호를 input으로 입력받은 후 그 문자열을 정수로 바꿔서
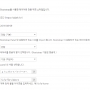
해당 게시글을 출력하는 부분에서 여러 유형의 오류가 발생하던데요.
len 함수와 아스키코드로 최대한 걸러내긴 했는데 제가 미처 발견하지 못한 버그가 있을 수도 있겠네요 ㅜㅜ
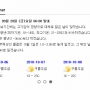
아쉽게도 게시글 목록의 페이지 넘김과 첨부파일 다운로드는 아직 지원하지 않습니다 T.T
제가 한가지 궁금한 점이 파싱하려는 페이지가 POST 방식으로 페이지 이동을 할 때
저는 파이어폭스 개발자도구에서 Convert form POSTs to GETs로 URL을 알아낸 후에
숫자 네자리로 된 파라미터를 정규식으로 파싱해서
URL과 파라미터를 조합하는 방식으로 파싱하려는 페이지에 접근했는데요.
상당히 조잡하고 주먹구구식 방법이지만 제 수준에서는 뾰족한 방법이 없더군요 ㅠㅠ
스포어의 고수님들께서 알고계시는 더 깔끔한 방법은 없을지 여쭤봅니다 ^^
허접한 글 읽어주셔서 감사합니다!
추신: 파이참을 추천해주신 humit 님께 감사합니다 ^-^
import urllib.request
import re
from bs4 import BeautifulSoup
url = "https://www.gosi.kr/cop/bbs/selectBoardList.do?bbsId=BBSMSTR_000000000131"
response = urllib.request.urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
results = soup.select("span.nobr")
a = 1
for result in results:
print(a, "\b. ", end='')
print(result.string)
a+=1
links = soup.find_all('a', href=True)
link_result = []
for link in links:
if link.get('href') == "#":
continue
this = link.get('href')
this2 = re.search('\'[1-9][0-9]{3}\'', this)
if this2:
link_result.append(this2.group()[1:5])
else:
continue
order = "m"
while order != "q" and order !="Q":
order = input("목록(l), 나가기(q) >> ")
if order == "l" or order == "L":
a = 1
for result in results:
print(a, "\b. ", end='')
print(result.string)
a+=1
elif order == "q" and order !="Q":
print ('종료합니다.\n')
elif len(order) > 1 and order != "10":
print ('잘못 입력하였습니다.\n')
continue
elif order == "10" or (ord(order) >= 48 and ord(order) <=57):
order2 = 0 - int(order)
codenumber = link_result[order2]
url1 = "https://www.gosi.kr/cop/bbs/selectBoardArticle.do;jsessionid=+xTTfDIqxVVspsCsttQPVTnn.node_cybergosiwas11?bbsId=BBSMSTR_000000000131&nttId="
url2 = "&bbsTyCode=BBST01&bbsAttrbCode=BBSA01&authFlag=Y&examgubunPosblAt=Y&anonymous=&examGubuncd=&searchCnd=0&searchWrd=&pageIndex=1"
url3 = url1 + codenumber + url2
response2 = urllib.request.urlopen(url3)
soup2 = BeautifulSoup(response2, 'html.parser')
results2 = soup2.select("div.board_con p")
for result2 in results2:
print(result2.text)
else:
print ('잘못 입력하였습니다.\n')
continue