
- 2
- 이니스프리
- 조회 수 414
안녕하세요?
롯데백화점 사이트를 크롤링 연습하다가 3일 동안 해결하지 못하여 부득이 여쭤봅니다 ㅠㅠ
신세계는 상대적으로 간단하던데 롯데는 제 수준에서 매우 어렵네요 ㅜㅜ
https://www.lotteshopping.com/benefitAndEvent/shoppingNewsSub
여기로 접속하면 기본적으로 '롯데백화점 본점'으로 연결되는데요.
'본점'을 클릭해서 '프리미엄 아울렛' -> '광명점'을 클릭합니다.
그러면 개발자도구의 네트워크 탭의 XHR 중에서 의심스러운(?) 내역을 확인할 수 있습니다.
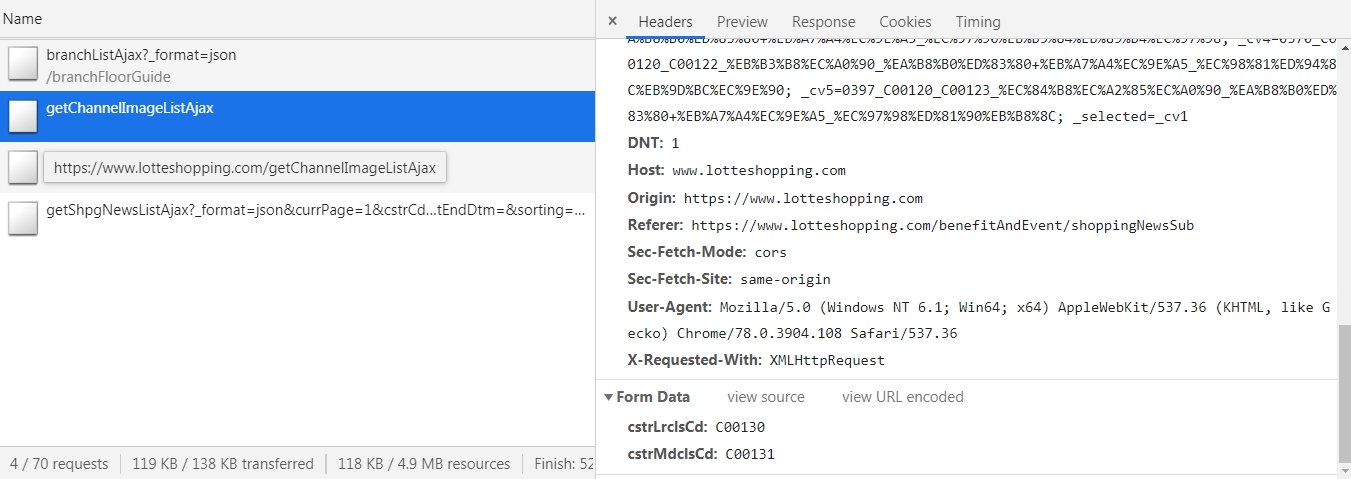
브라우저를 최대한 모방하기 위해 request_html로 세션을 유지한 상태에서 shoppingNewsSub로 get 요청을 한 후,
getChannelImageListAjax로 post 요청을 하여 폼을 전송하는 함수를 작성하였습니다.
from requests_html import HTMLSession
from bs4 import BeautifulSoup
def parse():
s = HTMLSession()
s.get('https://www.lotteshopping.com/benefitAndEvent/shoppingNewsSub')
gm = {
'cstrLrclsCd' : 'C00130',
'cstrMdclsCd' : 'C00131'
}
html = s.post('https://www.lotteshopping.com/getChannelImageListAjax', data=gm)
#soup = BeautifulSoup(html.content, 'html.parser')
print(html)그런데 shoppingNewsSub로의 요청에 대해서는 200 응답 코드가 나오는데, getChannelImageListAjax로의 요청에 대해서는 404 에러가 뜨는군요 ㅠㅠ
{"resultCode":"0000","channelImageList":[{"mgmChnlLrclsCd":null,"mgmChnlMdclsCd":null,"mgmMenuCd":null,"mgmTpCd":null,"expsrSequ":null,"dsplyStDt":null,"dsplyEndDt":null,"imgNm":"1115_세일_프리아울렛_혜택이벤트","imgExpl":"1115_세일_프리아울렛_혜택이벤트","imgPath":"/content/bnr/201911/C00130C00131C07903C0800110/","imgFle":"20191119172408601_6.jpg","bkgrndPath":null,"bkgrndFle":null,"urlUseYn":null,"urlPopupYn":"N","cnntUrl":null,"rgstOrgCd":null,"rgstDptNm":null,"rgstDtm":null,"rgprId":null,"mdfDtm":null,"mdfprId":null}],"resultMsg":"OK, 전송 성공"}
정상적이라면 이런 응답을 얻는 것으로 나오는데 말이죠.
requests_html은 기본적으로 mocked user-agent 등을 사용하여 브라우저처럼 인식되도록 한다고 알고 있는데요.
user-agent와 세션의 문제가 아니라면... 리퍼러 등을 의심해야 할텐데
제 나름대로 부족한 수준에서 리퍼러를 건드려봐도 이 사이트는 어렵네요 ㅜㅜ
이 정도로 어려운 수준을 극복해야 뭔가 한 단계 업그레이드가 될텐데 아직은 많이 부족한 것 같습니다.
이런 딴 짓을 하지 말고 다음주 COS 준비를 해야될텐데 말이죠.
고수님들의 조언을 부탁드립니다!
번번이 감사합니다 ^-^
작성자

댓글 2
") humit
humit 


앗 밤늦게 답변 달아주셔서 감사합니다~!
우선 header를 모두 포함해서 요청을 보내고나서, 하나씩 빼면서 시도하면 되는 것이군요.
그런 생각을 미처 못했네요 ㅠㅠ
제가 Accept와 관련된 부분을 저번에도 빼먹었던 것 같은데, 앞으로는 일단 헤더를 모두 포함해서 요청을 보내야겠네요.
REST API를 테스트하는 프로그램이 별도로 존재하는군요 ㄷㄷ
말씀해주신 프로그램 위주로 구글링해보니 많은 정보가 있네요~
앞으로 활용해보겠습니다 ^^
humit 님 덕분에 오늘도 많이 배웠습니다!
그럼 곧 기말고사 기간이실텐데 화이팅하시고, 감기 조심하세요!!
항상 감사드립니다 ^-^
+) 광명점을 비롯하여 여러 지점의 정보가 잘 크롤링되네요~ 다시 한 번 감사드립니다!

header에 Accept를 명시해주어야 동작하네요.
requests.post('https://www.lotteshopping.com/getChannelImageListAjax', {'cstrLrclsCd':'C00130', 'cstrMdclsCd':'C00131'}, headers={'Accept':'application/json, text/javascript, */*; q=0.01'}).content.decode('utf-8')
크롤링 시 팁을 드리자면, 저렇게 의심가는 요청을 찾은 다음에 저기에 나와 있는 헤더를 모두 포함해 요청을 보냅니다. 그리고 한 개씩 빼가면서 어떤 것이 있어야만 통과하는지 확인하는 방식으로 구현하시면 됩니다.
보통 이 과정을 할 때는 파이썬 코드를 짜지 않고 REST API를 테스트를 할 수 있도록 만들어진 프로그램을 사용합니다. 저의 경우에는 Postman (https://www.getpostman.com/)을 사용하고 있습니다. 참고로 Insomnia (https://insomnia.rest/)라는 비슷한 프로그램도 있습니다.
두 프로그램 모두 electron으로 구현이 되어 있습니다.