
안녕하세요? 비가 많이 내리는데 주말 잘 보내고 계시는가요? ^^
구글링해보면 selenium을 이용한 네이버 카페 크롤링 글은 많이 나오지만, requests를 이용한 예제는 흔하지 않더군요.
크롤링 연습을 하기 위해 requests 라이브러리만 사용하여 네이버 카페의 게시글 목록을 크롤링하여
일정수 이상의 리플이 달린 게시글만 텔레그램 알림을 하는 스크립트를 작성해보았습니다.
우선 간편한 크롤링을 위해 네이버 '모바일' 페이지를 활용하였습니다.
PC버전에서 페이지 목록을 직접 클릭하는 것과 달리, 모바일에서는 '더보기' 버튼을 클릭해서 목록을 넘기는데요.
humit 님께서 가르쳐주신 방법을 활용하여 ajax에서의 의심스러운 요청(?)을 찾아보았습니다.
브라우저 개발자 도구의 네트워크 탭에서 XHR을 살펴보면 ArticleListAjax.nhn를 통해 다음과 같은 폼을 전송하는 것을 확인할 수 있습니다.
저같은 초보도 어렵지 않게 발견할 수 있더군요 ^^
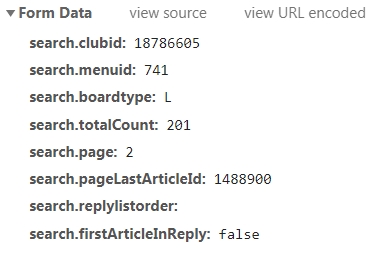
테스트해보니 모든 폼을 필요로 하는 것 같지는 않고, 일부만 params로 넣어주면 작동하는 것을 확인하였습니다.
이를 바탕으로 https://m.cafe.naver.com/hotellife 카페의 신용카드 게시판을 예제로 하여
게시글 목록 1~3페이지에서 리플이 70개 이상인 게시글 제목만 텔레그램으로 알림을 하는 크롤링을 해보겠습니다.
네이버 카페앱에는 이런 기능이 구현되어있지 않어서 실생활에 도움이 될 수 있을 것 같아서요 ^^
import requests, time, telegram, re
from bs4 import BeautifulSoup
## requests와 BeautifulSoup으로 카페 게시글 목록을 불러오는 함수 ##
def bs(url, page):
headers = { # 헤더를 넣지 않아도 작동하는 것을 확인했습니다.
'Content-Type': 'application/json; charset=utf-8',
'Accept-Language': 'ko-KR,ko;q=0.9,en-US',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
params = {
'search.clubid' : '18786605', # 카페 ID
'search.menuid' : '741', # 메뉴 ID
'search.boardtype' : 'L', # 보드타입 (반드시 필요로 하는 것은 아닌 것 같습니다.)
'search.page' : page # 불러올 페이지
}
html = requests.get(url, headers = headers, params = params)
soup = BeautifulSoup(html.text, 'html.parser')
return soup
## 게시글 제목과 리플 수를 파싱하여 리플 수가 일정 이상인 경우만 추출하는 함수 ##
def parse(url):
page = 0
result_title = []
result_reply = []
while page <= 3: # 1~3페이지를 불러옵니다.
soup = bs(url, page)
titles = soup.select('strong.tit') # 게시글 제목
for title in titles:
result_title.append(' '.join(title.text.strip().split()))
replys = soup.select('em.num') # 리플 수
for reply in replys:
result_reply.append(reply.text)
page += 1
time.sleep(0.5)
count = 0
final_list = []
while count < len(result_title):
if int(result_reply[count]) >= 70: # 리플이 70개가 넘는 글만 리스트에 담습니다.
final_list.append(result_title[count] + ' (' + result_reply[count] + ')')
count += 1
return final_list
## 최종결과 문자열에서 리플 수를 제외하는 정규식 처리 ##
def regex(string):
try: # 괄호 안 숫자가 두 글자인 경우
if re.compile(r'.+(?<=\(\d{2}\))').search(string).end() > 0:
result = string[:-5]
except: # 괄호 안 숫자가 세 글자인 경우 (네 글자인 경우는 상정하지 않았습니다.)
try:
if re.compile(r'.+(?<=\(\d{3}\))').search(string).end() > 0:
result = string[:-6]
except:
pass
return result
## TXT 파일로 결과를 저장하고 텔레그램으로 새 글을 알리는 함수 ##
def telegram_bot(titles):
bot = telegram.Bot(token='토큰을 입력하세요')
try:
chat_id = bot.getUpdates()[-1].message.chat.id
except:
chat_id = 챗아이디를 입력하세요 # 알림이 장시간 없는 경우에 발생하는 에러를 방지합니다.
try:
lines = [line.rstrip('\n') for line in open('ncafe.txt', 'r', encoding='utf8')]
except: # 파일이 존재하지 않는 경우를 예외처리합니다. (처음 실행하는 경우 에러가 발생하기 때문입니다.)
lines = ['no data']
check = 0
with open('ncafe.txt', 'w', encoding='utf8') as f: # TXT 파일을 업데이트합니다.
for title in titles:
for line in lines:
if regex(title) == regex(line):
check = 1
if check == 0: # 새 글만 텔레그램으로 알립니다.
bot.sendMessage(chat_id=chat_id, text=title)
print(title)
f.write(title + '\n')
if __name__ == '__main__':
url = 'https://m.cafe.naver.com/ArticleAllListAjax.nhn'
titles = parse(url)
telegram_bot(titles)게시글 제목과 리플 수를 한꺼번에 telegram_bot() 함수로 넘겨주다보니 리플 수가 업데이트 되어도 알림이 오는 문제가 발생하더군요 ㅠㅠ
이를 해결하기 위해 regex() 함수를 넣어서 제목만 따로 분리하여 if 문에서 동일한지 여부를 판단하는 방식을 택했습니다.
이는 게시글 제목과 리플 수를 따로 넘겨주어 처리하면 보다 간편히 처리할 수 있으므로 사실상 redundant한 부분인데
제가 정규식 후방탐색을 연습하기 위해 의도적으로 넣은 것입니다 ^^;
스포어에는 파이썬 고수님들도 많이 계시던데 저같은 아마추어의 허접한 스크립트를 번번이 읽어주셔서 감사합니다 :)
그럼 즐거운 주말 되시고, 이번주에는 서울도 영하 4도까지 기온이 떨어진다는데 다들 감기 조심하세요!


 [Python] Google Image Search 결과를 받아오기
[Python] Google Image Search 결과를 받아오기

") humit
humit
+ 해당 문제의 경우 정규식을 사용할 때 후방 탐색을 하지 않더라도 $를 활용하여 똑같은 기능을 할 수 있도록 코드를 작성할 수도 있습니다. (댓글 수가 맨 뒤에 오기 때문)
re.compile('\\((\d+)\\)$').search('게시물 제목(1) (10)').group(1)