
안녕하세요?
일부 지방에는 비가 많이 왔다고 하던데 비 피해는 없으셨는지요?
네이버 모바일 이미지 검색(DataLab, https://m.search.naver.com/search.naver)에서 검색된 기사들의 URL을 얻고
그 URL을 통해서 기사 본문에 접근하여 이미지를 멀티스레드로 다운받은 후에
Pillow 라이브러리를 이용하여 세로로 하나의 파일로 병합(merge)하는 스크립트를 작성하였습니다.
네이버의 기사에서는 최대한 본문의 모든 파일을 다운받는 방향으로 하였고,
다른 신문사의 기사에서는 meta태그에서 이미지를 다운받는 방법을 택했습니다.
requests 모듈로 파일을 다운받는 부분은 멀티스레드를 이용하여 I/O 바운드 처리를 하였습니다.
pillow를 이용한 이미지 처리를 연습하는 것에 중점을 두고 스크립트를 작성했네요.
부족한 점이 많지만 일단 스크립트를 올립니다 ㅠㅠ
import sys, requests, urllib.request, os, time
from bs4 import BeautifulSoup
from PIL import Image, ImageFile
from concurrent.futures import ThreadPoolExecutor
## 이미지 병합 파트 ##
def img_processing(img_list): # 이미지 병합 처리 함수
images = map(Image.open, img_list)
widths, heights = zip(*(i.size for i in images))
max_width = max(widths)
total_height = sum(heights) + (len(img_list)-1)*50 # 이미지 길이의 총합에 50px씩 여유를 줍니다.
new_im = Image.new('RGB', (max_width, total_height), (255, 255, 255)) # 바탕은 흰색입니다.
images = map(Image.open, img_list)
y = 0
for im in images:
x = int((max_width - im.size[0])/2) # 이미지의 x축을 센터에 맞춰줍니다.
new_im.paste(im, (x, y))
y += im.size[1]+50
return new_im
def merge_image_main(img_list, directory): # 이미지 관련 메인함수
complete_image = img_processing(img_list)
file_name = directory + '\\merge ' + directory.split('\\')[-1] + ' x' + str(len(img_list)) + '.jpg'
complete_image.save(file_name, quality=95) # 해상도를 95로 지정했습니다.
print('Success : ' + file_name)
## 이하 파싱 파트 ##
def bs(url): # requests 모듈과 beatifulsoup 모듈로 사이트의 html을 불러오는 함수
headers = {'Accept-Language': 'ko-KR,ko;q=0.9,en-US', 'User-Agent': 'Mozilla/5.0 (Linux; Android 8.1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3384.0 Mobile Safari/537.36'}
req = requests.get(url=url, headers=headers, timeout=5)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
return soup
def parse_naversearch(keyword): # 네이버 검색결과에서 a태그를 추출하는 함수
search_url = 'https://m.search.naver.com/search.naver?where=m_image&sm=mtb_jum&query=' + keyword
soup = bs(search_url)
target_div = soup.find('div', {'class':'photo_grid _grid'})
news_urls = target_div.select('a')
return news_urls
def get_article_url(keyword): # 기사 본문의 URL을 얻어오는 함수
search_url = 'https://m.search.naver.com/search.naver?where=m_image&sm=mtb_jum&query=' + keyword
soup = bs(search_url)
div_time_tag = soup.find('div', {'class':'timeline_header'})
article_date = div_time_tag.select_one('time').text.replace('.', '')[2:]
target_div = soup.find('div', {'class':'photo_grid _grid'})
news_urls = target_div.select('a')
naver_urls = []
other_urls = []
for news_url in news_urls:
if 'naver' in news_url['href']:
changed_url = 'https://entertain.naver.com/read?' + news_url['href'].split('?')[-1]
naver_urls.append(changed_url)
else:
other_urls.append(news_url['href'])
return naver_urls, other_urls, article_date
def download_naver_img(naver_urls, dir): # 네이버 기사의 이미지를 다운받는 함수
naver_img_urls = []
executer1 = ThreadPoolExecutor(max_workers=4)
for naver_url in naver_urls:
soup = bs(naver_url)
count = 1
while True:
id_name = 'img' + str(count)
try: # 네이버 기사에서 img1, img2 ... 이런 식으로 id가 붙는 이미지를 모두 찾습니다.
target_img = soup.find('img', {'id':id_name})
if target_img:
print(target_img['src'])
naver_img_urls.append(target_img['src'])
count += 1
else:
break
except:
print('Failed to get image URL.')
break
for url in naver_img_urls:
executer1.submit(file_download, url, dir) # 멀티스레드로 다운받습니다.
print('네이버 : ' + str(len(naver_img_urls)) + '개')
return naver_img_urls
def get_image_size(url): # 이미지 사이즈를 구하는 함수
file = urllib.request.urlopen(url)
parse = ImageFile.Parser()
while True:
data = file.read(1024)
if not data:
break
else:
parse.feed(data)
if parse.image:
width = parse.image.size[0]
return width
file.close()
return 'Error!'
def download_other_img(other_urls, dir): # 다른 신문사의 이미지를 다운받는 함수
executer2 = ThreadPoolExecutor(max_workers=4)
other_img_urls = []
for other_url in other_urls:
soup = bs(other_url)
try:
tags = soup.find_all('meta', {'property':'og:image'}) # meta태그에서 이미지를 검색합니다.
downloaded = ''
for tag in tags:
if tag['content'] and tag['content'] != downloaded: # 중복된 다운로드를 피합니다.
try:
width = get_image_size(tag['content'])
if width > 300: # 이미지 가로사이즈가 300 이상인 경우만 다운받습니다.
other_img_urls.append(tag['content'])
downloaded = tag['content']
print(downloaded)
for url in other_img_urls:
executer2.submit(file_download, url, dir)
except:
print('네이버 이외의 사이트에서 파싱에 실패했습니다.')
except:
print('네이버 이외의 사이트에서 파싱에 실패했습니다.')
print('네이버 이외의 사이트 : ' + str(len(other_img_urls)) + '개')
return other_img_urls
def file_download(url, directory): # requests 모듈을 이용하여 파일을 다운받는 함수
headers = {'Accept-Language': 'ko-KR,ko;q=0.9,en-US', 'User-Agent': 'Mozilla/5.0 (Linux; Android 8.1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3384.0 Mobile Safari/537.36'}
response = requests.get(url=url, headers=headers, timeout=5)
filename = url.split('/')[-1].split('?')[0]
path_file_name = directory + '\\' + filename
if response.status_code == 200:
with open(path_file_name, 'wb') as f:
f.write(response.content)
return
def main(keyword): # 메인함수
article_urls = get_article_url(keyword)
directory = os.getcwd() + '\\' + keyword + ' - ' + article_urls[2]
if not os.path.exists(directory):
os.makedirs(directory) # 날짜와 키워드를 조합하여 폴더를 생성합니다.
naver_img_list = download_naver_img(article_urls[0], directory)
other_img_list = download_other_img(article_urls[1], directory)
total_list = naver_img_list + other_img_list
print('총' + str(len(total_list)) + '개의 파일을 다운로드하였습니다.')
file_list = []
for name in total_list:
file_list.append(directory + '\\' + name.split('/')[-1].split('?')[0])
time.sleep(1) # 잠깐 쉬지 않으면 다운로드가 완료되기 전에 이미지 처리로 넘어가서 에러가 발생할 수 있습니다.
merge_image_main(file_list, directory)
if __name__ == "__main__":
main('itzy')실행하면 다음과 같이 폴더가 생성된 후 파일이 다운로드되고, 모든 파일이 병합된 이미지가 생성됩니다.
원래는 '방탄소년단'으로 검색했으나 90개가 넘는 이미지가 다운로드되어
Pillow가 처리할 수 있는 픽셀의 범위를 초과하게 되어 이미지 병합에 실패했습니다 ㄷㄷ
그래서 'itzy'를 검색어로 사용했습니다.

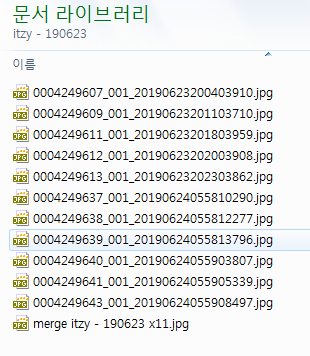
보시다시피 11개의 이미지가 모두 다운로드 되었음을 확인할 수 있습니다.

각 사진 사이에 50px씩 여유를 두어 한 개의 이미지 파일로 병합된 것을 확인할 수 있습니다 ^^
사진의 저작권은 네이버와 각 신문사 측에 있으니 개인적인 용도로만 사용해주시면 감사하겠습니다.
이번 스크립트를 작성하면서 느낀 점을 간략히 말씀드리려고 합니다.
1. 멀티프로세싱/멀티스레드 처리는 역시 어렵네요 ㅠㅠ
멀티스레드로 파싱한 결과를 리스트에 append하면 값이 안 넘어오네요.
그렇다면 각 스레드마다 파일 다운까지 완료해야 하는데 전반적인 함수의 구조를 다시 짜지 않으면 힘들겠더군요 ㅠㅠ
이 부분은 더 공부를 해야될 것 같습니다.
2. 네이버 모바일 이미지 검색 화면에서 과거의 모든 이미지를 검색하려면 스크롤을 해야하기 때문에
결국 selenium을 사용하는 방법밖에 없을 것 같네요.
그런데 selenium을 사용하면 처리속도가 지금보다 훨씬 떨어지겠죠 ㅠㅠ
3. 전반적으로 제 파싱방법이 사이트 리뉴얼에 취약한데
인강에서 뵐 수 있는 직업적으로 파싱을 하시는 분들은 어떤 방법을 택하는지 궁금하네요 ^^
네이버와 디시인사이드를 파싱해보니 파싱이란 어떤 것인지 조금이나마 느껴보았네요.
앞으로는 파싱한 결과를 DB로 직접 넣는 것에 포커스를 두고 연습해야 될 것 같아요.
그럼 스포어 회원님들께서도 편안한 밤 되시고 내일 즐거운 불금 되세요 ^^
부족한 글을 읽어주셔서 감사합니다!


 [아미나] Dropbox API를 이용한 이미지 호스팅 보드스킨
[아미나] Dropbox API를 이용한 이미지 호스팅 보드스킨


") humit
humit
멀티스레드까지 하시다니! 역시 고급개발자 이니스프리님!
방탄소년단도 결과가 나오게 해주세요!